Chapter 3 Describing Data using plots
3.1 Seminar
In the last seminar, we looked at getting to know our data with simple descriptors of central tendency and dispersion. In the lecture videos, we introduced plots. We showed you that, through visualisation, you can take data description further. This week, we continue talking about plots and get to grips with how to create them in R using ggplot().
3.1.1 Loading Dataset in CSV Format
In this seminar, we load a file in comma separated format (.csv). The load() function from last week works only for the native R file format. To load our csv-file, we use the read.csv() function.
Our dataset contains data about London Boroughs:
# load a dataset in a csv file
pop <- read.csv("https://raw.githubusercontent.com/QMUL-SPIR/Public_files/master/datasets/census-historic-population-borough.csv")Go ahead and (1) check the dimensions of pop, (2) the names of the variables of the dataset, (3) print the first six rows of the dataset.
# the dimensions: rows (observations) and columns (variables)
dim(pop)[1] 33 24# the variable names
names(pop) [1] "Area.Code" "Area.Name" "Persons.1801" "Persons.1811" "Persons.1821"
[6] "Persons.1831" "Persons.1841" "Persons.1851" "Persons.1861" "Persons.1871"
[11] "Persons.1881" "Persons.1891" "Persons.1901" "Persons.1911" "Persons.1921"
[16] "Persons.1931" "Persons.1939" "Persons.1951" "Persons.1961" "Persons.1971"
[21] "Persons.1981" "Persons.1991" "Persons.2001" "Persons.2011"# top 6 rows of the data
head(pop) Area.Code Area.Name Persons.1801 Persons.1811 Persons.1821
1 00AA City of London 129000 121000 125000
2 00AB Barking and Dagenham 3000 4000 5000
3 00AC Barnet 8000 9000 11000
4 00AD Bexley 5000 6000 7000
5 00AE Brent 2000 2000 3000
6 00AF Bromley 8000 9000 11000
Persons.1831 Persons.1841 Persons.1851 Persons.1861 Persons.1871 Persons.1881
1 123000 124000 128000 112000 75000 51000
2 6000 7000 8000 8000 10000 13000
3 13000 14000 15000 20000 29000 41000
4 9000 11000 12000 15000 22000 29000
5 3000 5000 5000 6000 19000 31000
6 12000 14000 16000 22000 42000 62000
Persons.1891 Persons.1901 Persons.1911 Persons.1921 Persons.1931 Persons.1939
1 38000 27000 20000 14000 11000 9000
2 19000 27000 39000 44000 138000 184000
3 58000 76000 118000 147000 231000 296000
4 37000 54000 60000 76000 95000 179000
5 65000 120000 166000 184000 251000 310000
6 83000 100000 116000 127000 165000 237000
Persons.1951 Persons.1961 Persons.1971 Persons.1981 Persons.1991 Persons.2001
1 5000 4767 4000 5864 4230 7181
2 189000 177092 161000 149786 140728 163944
3 320000 318373 307000 293436 284106 314565
4 205000 209893 217000 215233 211404 218301
5 311000 295893 281000 253275 227903 263466
6 268000 294440 305000 296539 282920 295535
Persons.2011
1 7375
2 185911
3 356386
4 231997
5 311215
6 3093923.1.2 Plotting data with R
Tools to create high quality plots have become one of R’s greatest assets. The standard installation of R has graphic functionality built in to produce very simple plots. For example we can plot the relationship between the London population in 1811 and 1911:
# left of the comma is the x-axis, right is the y-axis. Also note how we are using the $ command to select the columns of the data frame we want.
plot(pop$Persons.1811,pop$Persons.1911)
You should see a very simple scatter graph.
3.1.3 ggplot2
A different, more flexible method of creating plots in R requires the ggplot2 package, from the tidyverse (more on this next week). There are many hundreds of packages in R each designed for a specific purpose. These are not installed automatically, so each one has to be downloaded and then we need to tell R to use it. We have already installed ggplot2 for you, so you just need to call it into your working environment using the library() command, which tells R that it will be required.
library("ggplot2")ggplot2 is an implementation of the ‘Grammar of Graphics’ (Wilkinson 2005) - a general scheme for data visualisation that breaks up graphs into semantic components such as scales and layers. ggplot2 can serve as a replacement for the base graphics in R and contains a number of default options that match good visualisation practice. This is an increasingly popular way to visualise data in R, because it is both more flexible and more powerful than the base plot approach.
While the instructions below take you through the approach step-by-step, you are encouraged to deviate from them (trying different colours for example) to get a better understanding of what we are doing. For further help, ggplot2 is one of the best documented packages in R and has an extensive website. Good examples of graphs can also be found on the R Cookbook website. We’ll name our graphs using ‘gg’ plus some word indicating their content, but remember that these names are arbitrary.
gg_pops <- ggplot(data = pop,
mapping = aes(x = Persons.1811, y = Persons.1911))What you have just done is set up a ggplot object in which you say where you want the input data to come from (the data = argument) -– in this case it is the pop object. The column headings within the aes() brackets refer to the parts of that data frame you wish to use (the variables Persons.1811 on the x axis and Persons.1911 on the y axis), specified by the mapping = argument. aes is short for ‘aesthetics that vary’ – this is a complicated way of saying the data variables used in the plot. In practice, these arguments are used so frequently that it is quite rare to see data = and mapping = typed out like this. As so many people use ggplot, and essentially every ggplot starts with a first line like this, the code gg_pops <- ggplot(pop, aes(Persons.1811, Persons.1911)) is perfectly clear and legible to most R users.
If you just type gg_pops and hit enter, R will not plot any data, just axes. This is because you have not told ggplot what you want to do with the data. We do this by adding so-called ‘geoms’, in this case geom_point(), to create a scatter plot.
gg_pops + geom_point()
You can already see that this plot is looking a bit nicer than the one we created with the base plot() function used above. Within the geom_point() brackets you can alter the appearance of the points in the plot. Try something like gg_pops + geom_point(colour = "red", size=2) and also experiment with your own colours/sizes. If you want to colour the points according to another variable it is possible to do this by adding the desired variable into the aes() section after geom_point(). Here will indicate the size of the population in 2011 as well as the relationship between in the size of the population in 1811 and 1911.
gg_pops + geom_point(aes(colour = Persons.2011))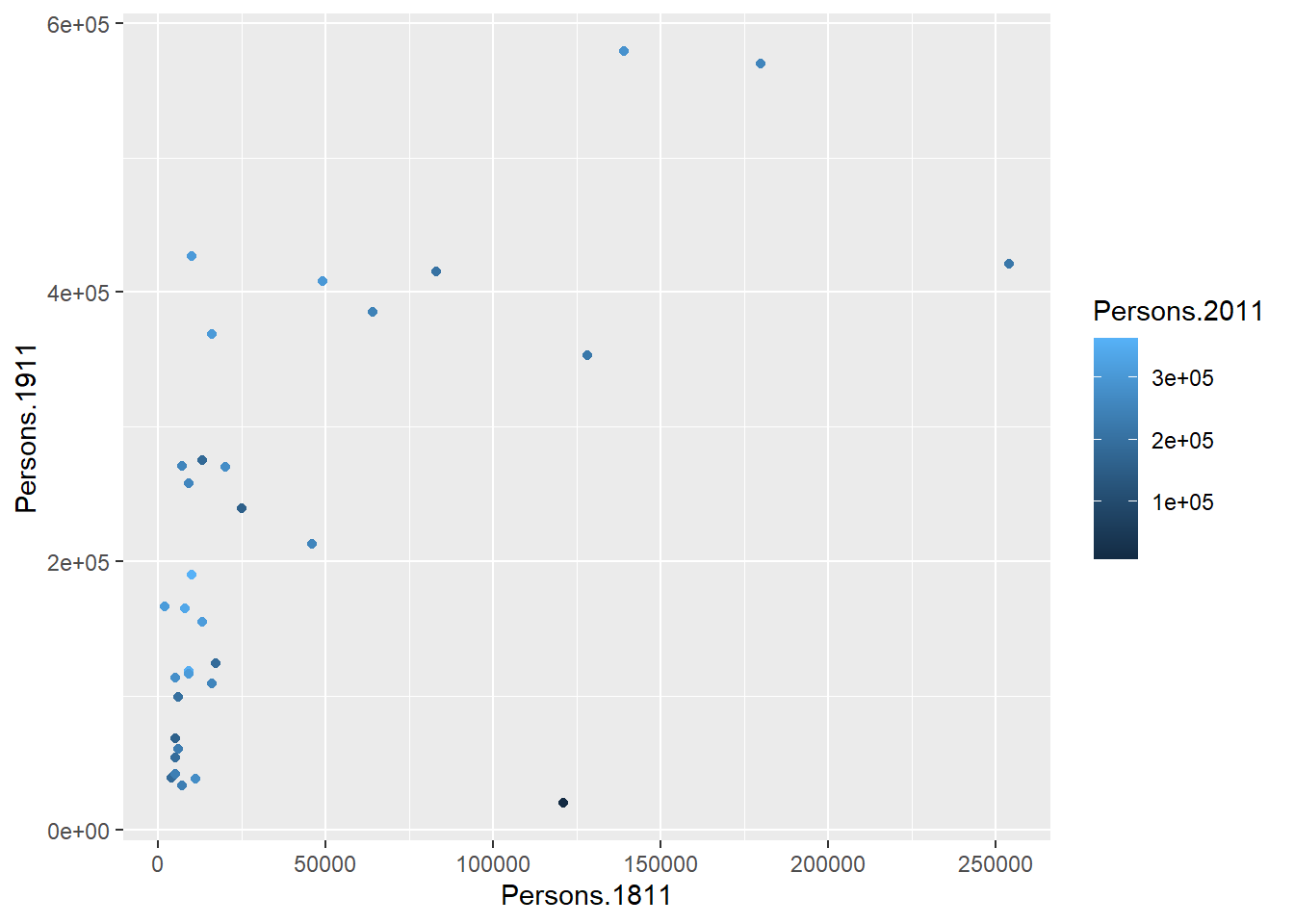
You will notice that ggplot has also created a key that shows the values associated with each colour. In this slightly contrived example it is also possible to resize each of the points according to the Persons.2011 variable.
gg_pops + geom_point(aes(size = Persons.2011))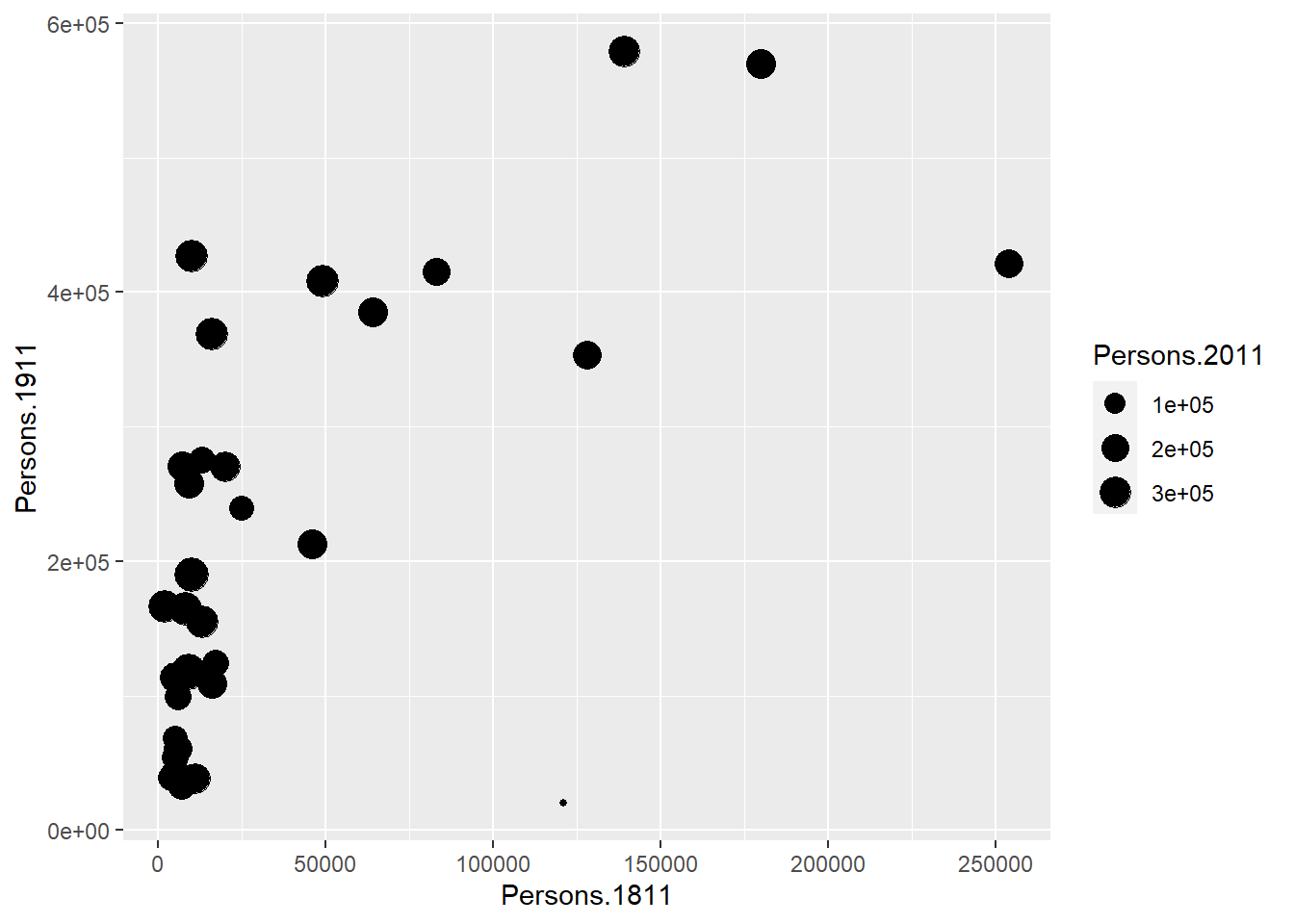
The real power of ggplot2 lies in its ability build a plot up as a series of layers. This is done by stringing plot functions (geoms) together with the + sign. In this case we can add a text layer to the plot using geom_text().
gg_pops +
geom_point(aes(size = Persons.2011)) +
geom_text(size = 2,
colour = "red",
aes(label = Area.Name))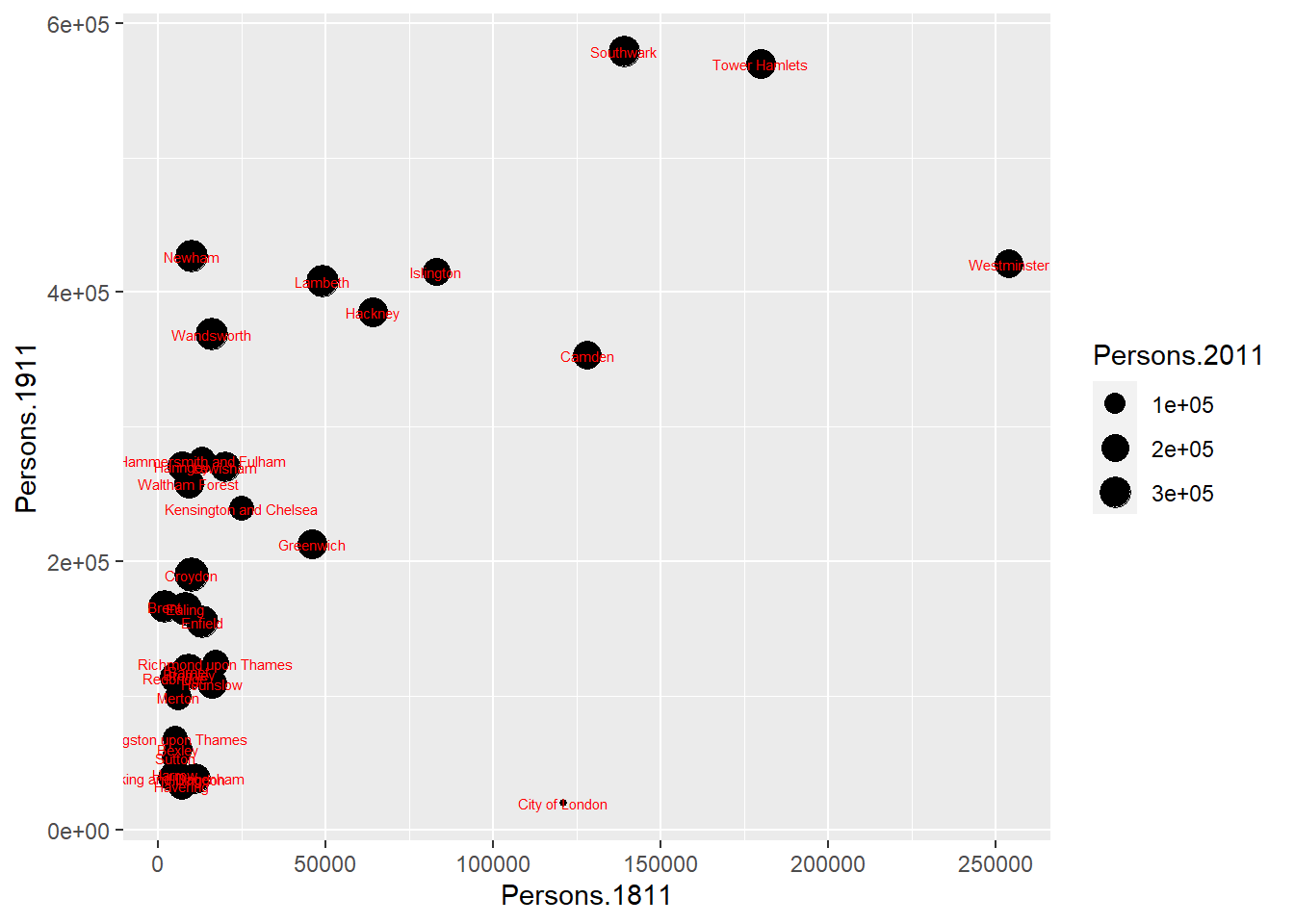
This idea of layers (or geoms) is quite different from the standard plot functions in R, but you will find that each of the functions does a lot of clever stuff to make plotting much easier (see the ggplot2 documentation for a full list). The above code adds London Borough labels to the plot over the points they correspond to. This isn’t perfect since many of the labels overlap but they serve as a useful illustration of the layers. To make things a little easier the plot can be saved as a PDF using the ggsave() command. When saving the plot can be enlarged to help make the labels more legible.
ggsave("first.ggplot.pdf", scale = 2)ggsave only works with plots that were created with ggplot. Within the brackets you should create a file name for the plot - this needs to include the file format (in this case .pdf you could also save the plot as a .jpg file). The file will be saved to your working directory (or, in Rstudio cloud, your project). The scale controls how many times bigger you want the exported plot to be than it currently is in the plot window. Once executed you should be able to see a PDF file in your working directory.
3.1.4 Histograms
For the rest of this tutorial we will change our dataset to one containing all of Donald Trump’s tweets from the 2016 election up to 2018. It is in Rds format so we load it using readRDS.
# read in the trump datafile
trump_twitter <- readRDS(url("https://github.com/QMUL-SPIR/Public_files/blob/master/datasets/trump_twitter.rds?raw=true"))#Check that the data have been loaded in correctly by viewing the top 6 rows with the head() command.
head(trump_twitter) text
1 Happy Birthday @DonaldJTrumpJr!\nhttps://t.co/uRxyCD3hBz
2 Russians are playing @CNN and @NBCNews for such fools - funny to watch, they don't have a clue! @FoxNews totally gets it!
3 Join @AmerIcan32, founded by Hall of Fame legend @JimBrownNFL32 on 1/19/2017 in Washington, D.C.… https://t.co/9WJZ8iTCQV
4 Great move on delay (by V. Putin) - I always knew he was very smart!
5 My Administration will follow two simple rules: https://t.co/ZWk0j4H8Qy
6 'Economists say Trump delivered hope' https://t.co/SjGBgglIuQ
created_at retweet_count favorite_count
1 2016-12-31 13:58:12 9529 55601
2 2016-12-30 17:18:18 23213 84254
3 2016-12-30 14:46:55 7366 25336
4 2016-12-30 14:41:33 34415 97669
5 2016-12-29 09:54:21 11330 45609
6 2016-12-28 17:06:28 13919 51857#To get a sense of how large the data frame is, look at how many rows you have
nrow(trump_twitter)[1] 2470You will notice that the data table has 4 columns and 2476 rows. The variables are the text content of the tweet, when it was posted, how many times it was retweeted, and how many times it was favourited.
We could describe this data as we did last week, by for example calculating the mean number of times Trump is retweeted, and the standard deviation of this estimate. We could also look at this distribution visually, in the form of a histogram. This can be done very easily in ggplot.
gg_retweets <- ggplot(trump_twitter, aes(x = retweet_count))The ggplot(trump, aes(x = retweet_count)) section means create a generic plot object (called gg_retweets) from the trump object using the retweet_count column as the data for the x axis. Remember the data variables are required as aesthetics parameters so the retweet_count appears in the aes() brackets.
To create the histogram you need to add the relevant geom:
gg_retweets + geom_histogram()`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.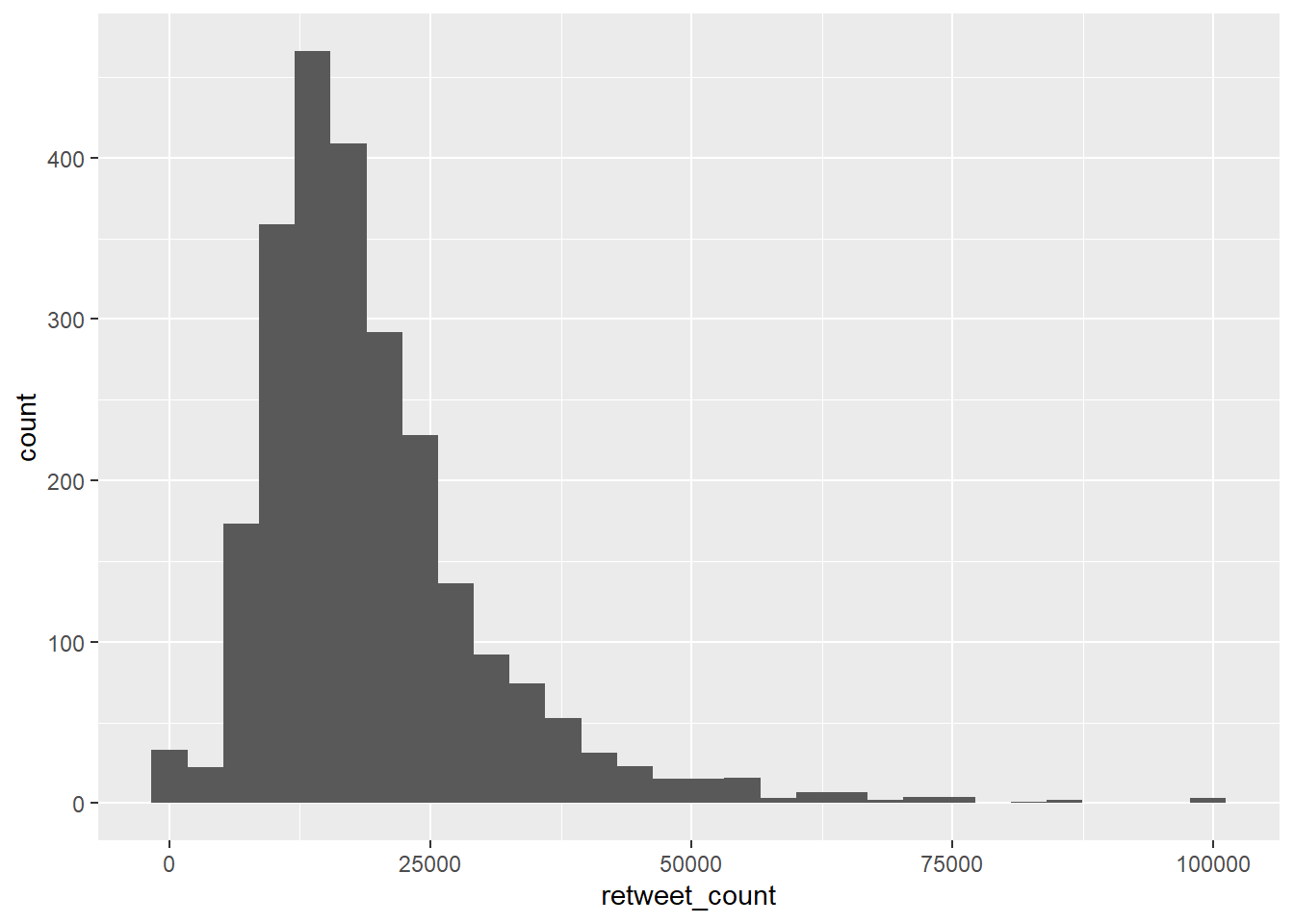
The height of each bar shows the count of the datapoints and the width of each bar is the value range of datapoints included. If you want the bars to be thinner (to represent a narrower range of values and capture some more of the variation in the distribution) you can adjust the binwidth. Binwidth controls the size of ‘bins’ that the data are split up into. We will discuss this in more detail later in the course, but put simply, the bigger the bin (larger binwidth) the more data it can hold. Try:
gg_retweets + geom_histogram(binwidth = 100)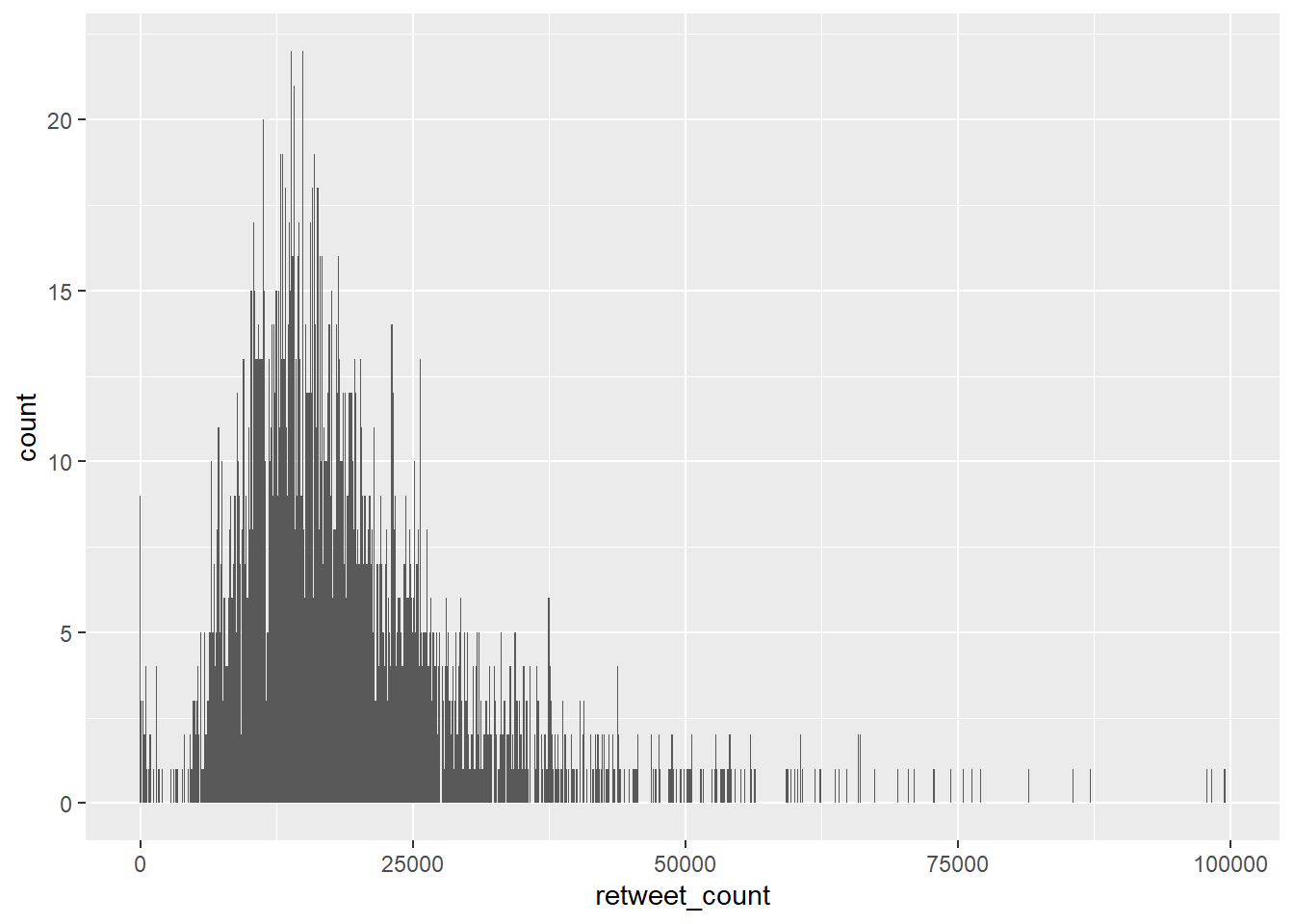
You can also overlay a density distribution over the top of the histogram. This will be discussed in more detail later in the term, but think of the plotted line as a summary of the underlying histogram. For this we need to produce a second plot object that says we wish to use the density distribution as the y variable.
gg_trump_dens <- ggplot(trump_twitter, aes(x = retweet_count, y = ..density..))
gg_trump_dens + geom_histogram() + geom_density(fill = NA, colour = "red")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.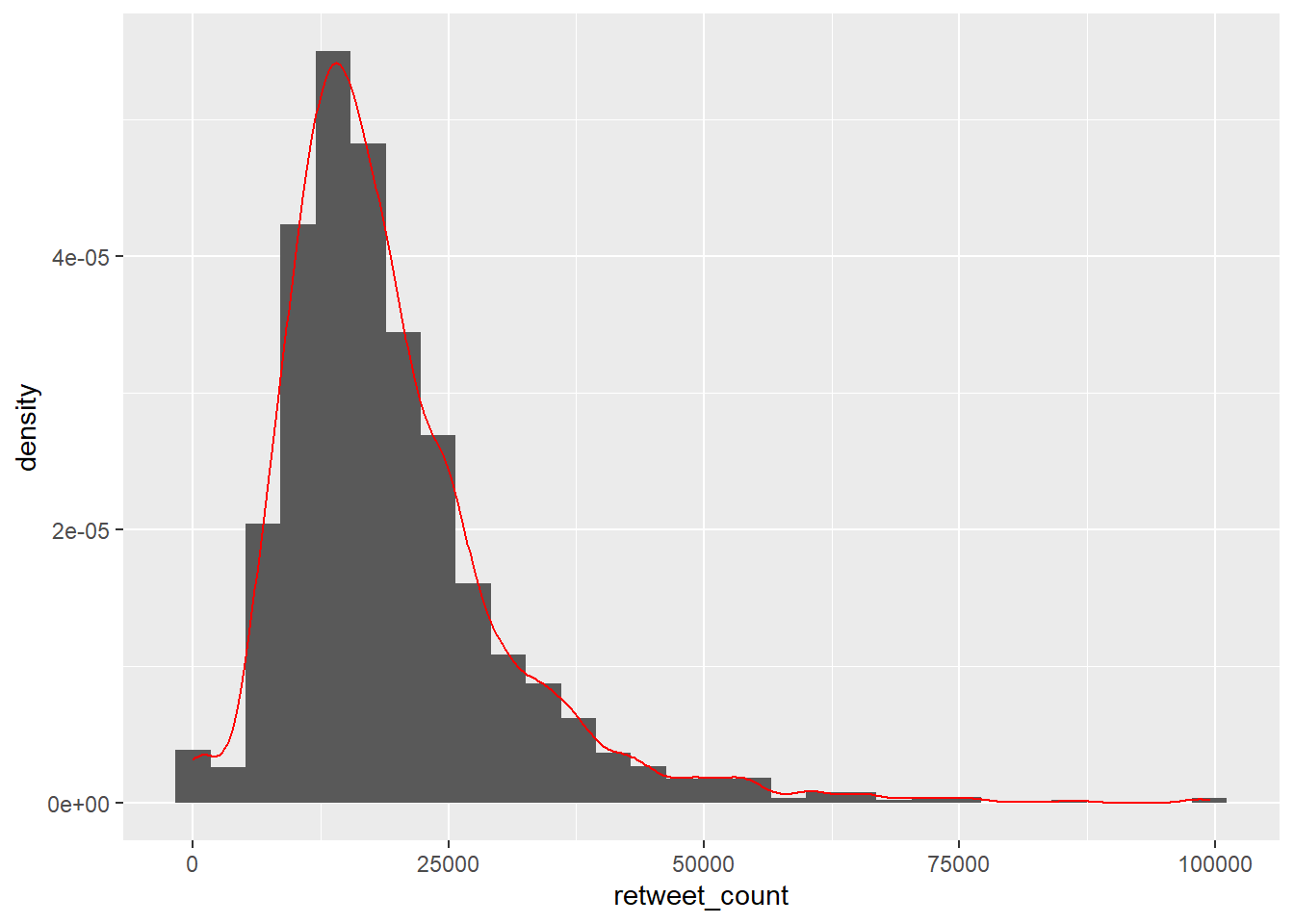
3.1.5 Box and Whisker plots
In addition to histograms, a type of plot that shows the core characteristics of the distribution of values within a dataset is a box and whisker plot (boxplot for short). These too can be easily produced in R.
The diagram below illustrates the components of a box and whisker plot.
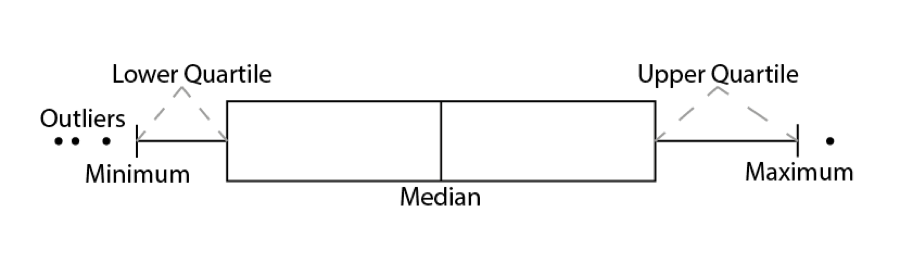
We can create a third plot object for this from the input object:
# note that the `retweet_count` column is now y and not x and that we have specified x = 1. This aligns the plot to the x-axis (any single number would work).
gg_box <- ggplot(trump_twitter, aes(x = 1, y = retweet_count))And then convert it to a boxplot using the geom_boxplot() command.
gg_box + geom_boxplot()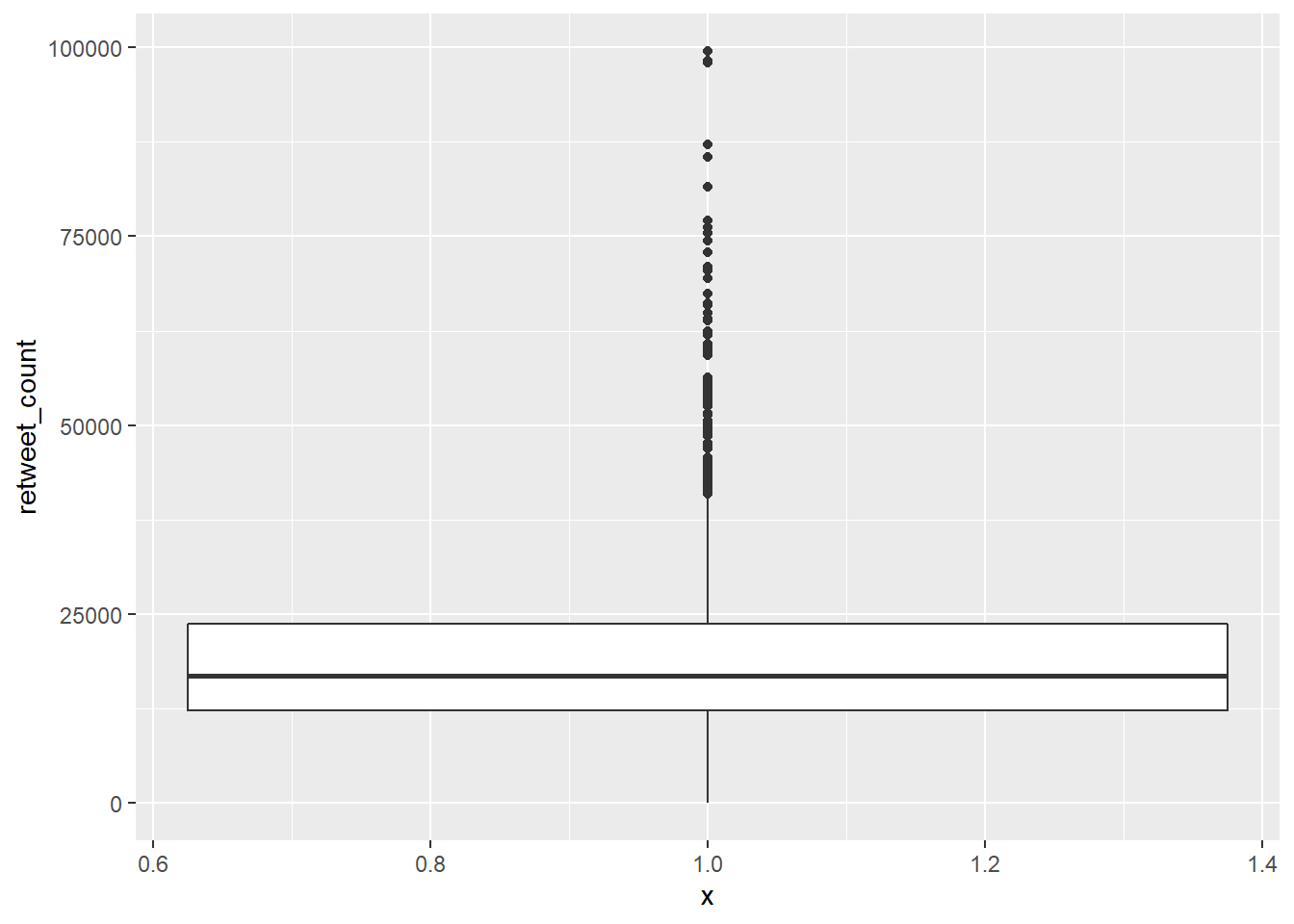
3.1.6 Facets
These plot examples provide good overall descriptions of the variable we’re interested in: how often Trump is retweeted. But sometimes we want to know if such a variable differs according to another variable. To see this, take the following simple example. The heights object contains the reported heights of a group of students.
# read in the trump datafile
heights <- readRDS(url("https://github.com/QMUL-SPIR/Public_files/blob/master/datasets/heights.rds?raw=true"))We can plot this as a histogram:
# histogram
gg_height <- ggplot(data = heights, aes(x = height)) +
geom_histogram()
gg_height`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.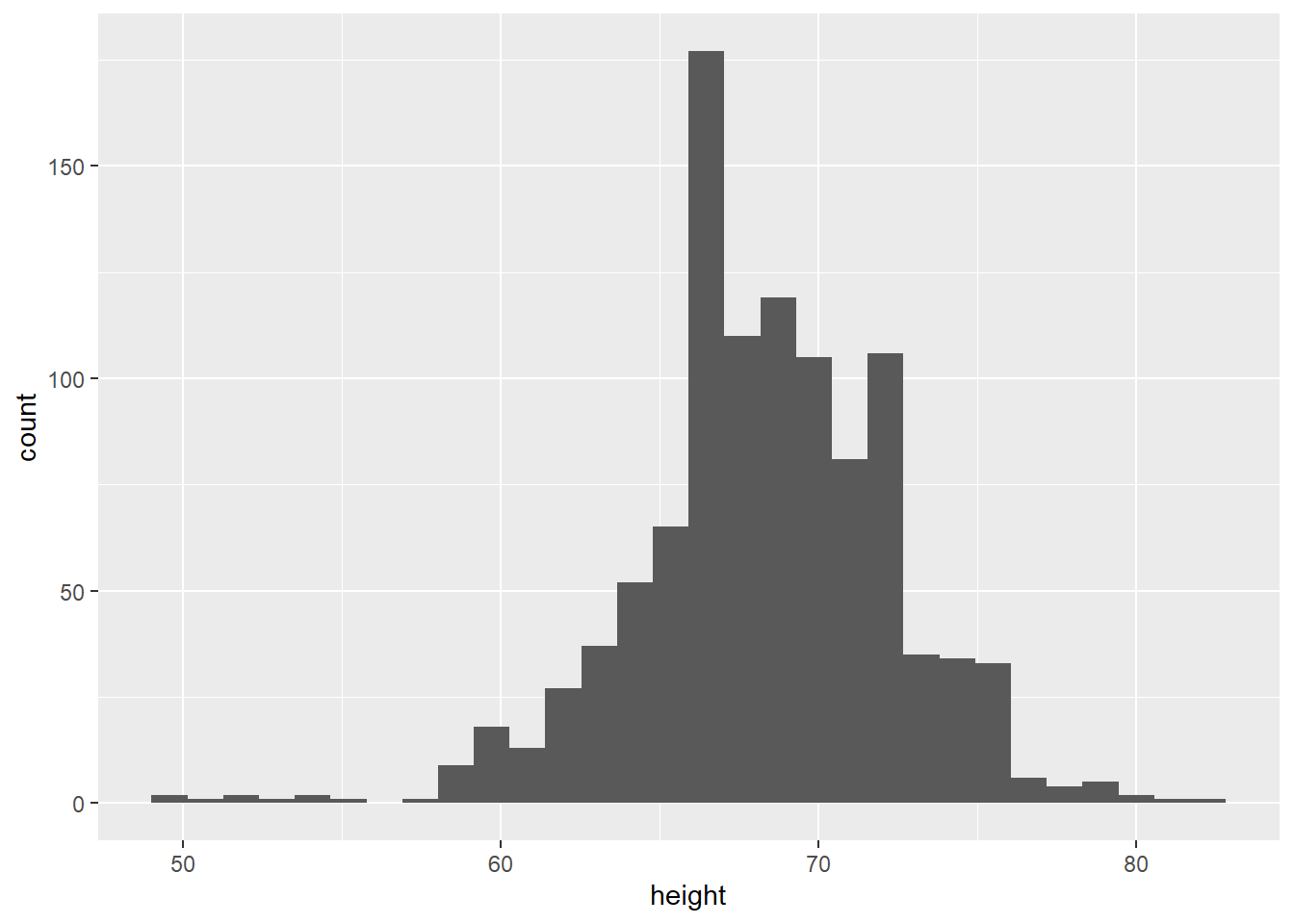
We could also plot this as a boxplot:
# boxplot
gg_height_box <- ggplot(data = heights, aes(x = 1, y = height)) +
geom_boxplot()
gg_height_box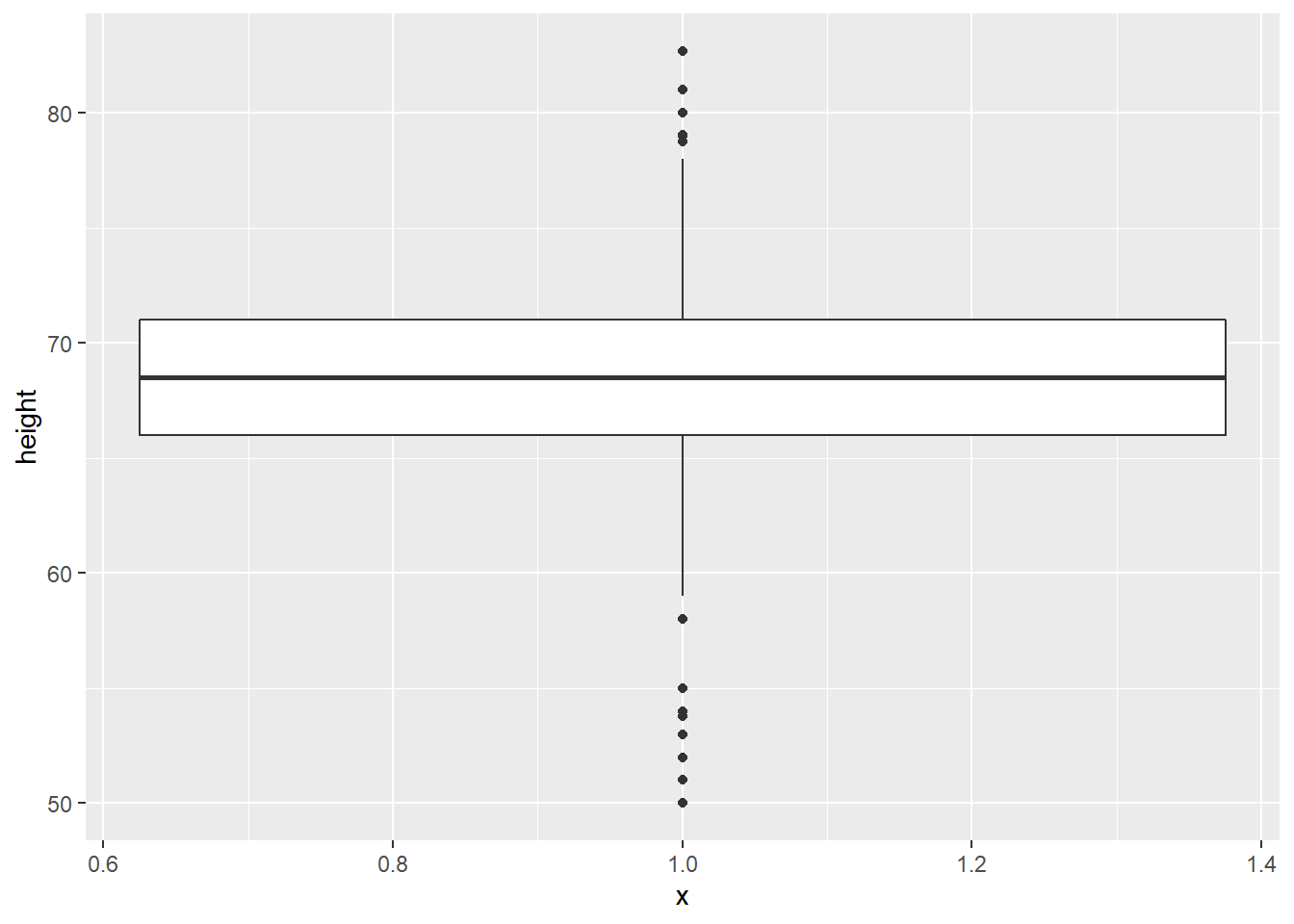
However, we also have data on the students’ reported sex. We know that, on average, men tend to be taller than women. So, we can look at their heights separately using facet_wrap, which splits the plot into different ‘facets’:
# histogram facets
gg_height + facet_wrap(~ sex)`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.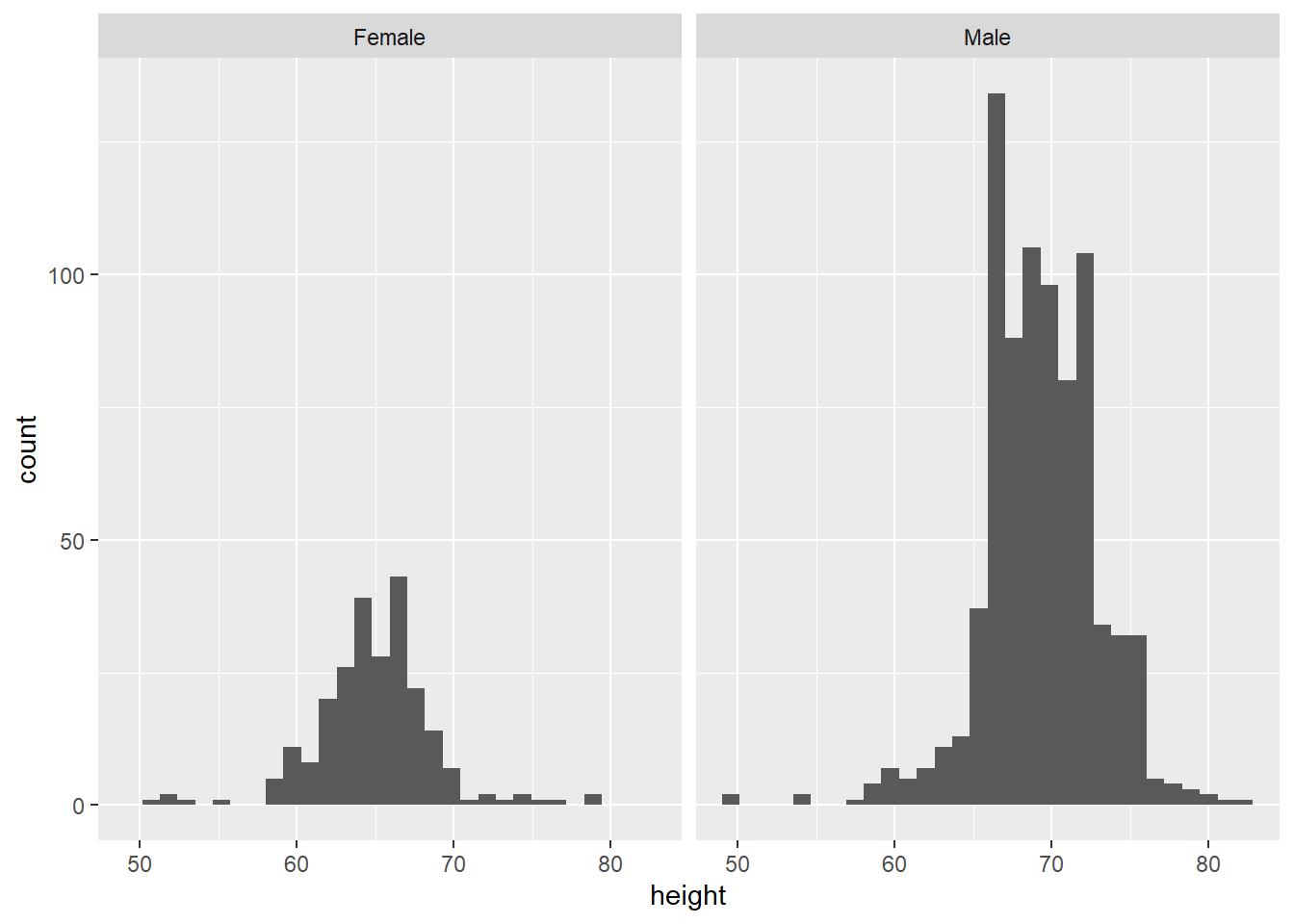
The variable after the ‘tilde’ (~) is used to create the different ‘facets’ or panes. This reveals, indeed, that male students are more clustered around taller heights, while female students tend to be less tall on average. This also shows us that we seem to have far more male students in the dataset.
We can do the same thing with virtually any plot, as long as we have a variable to facet by. This also works for boxplots:
# boxplot facets
gg_height_box + facet_wrap(~ sex)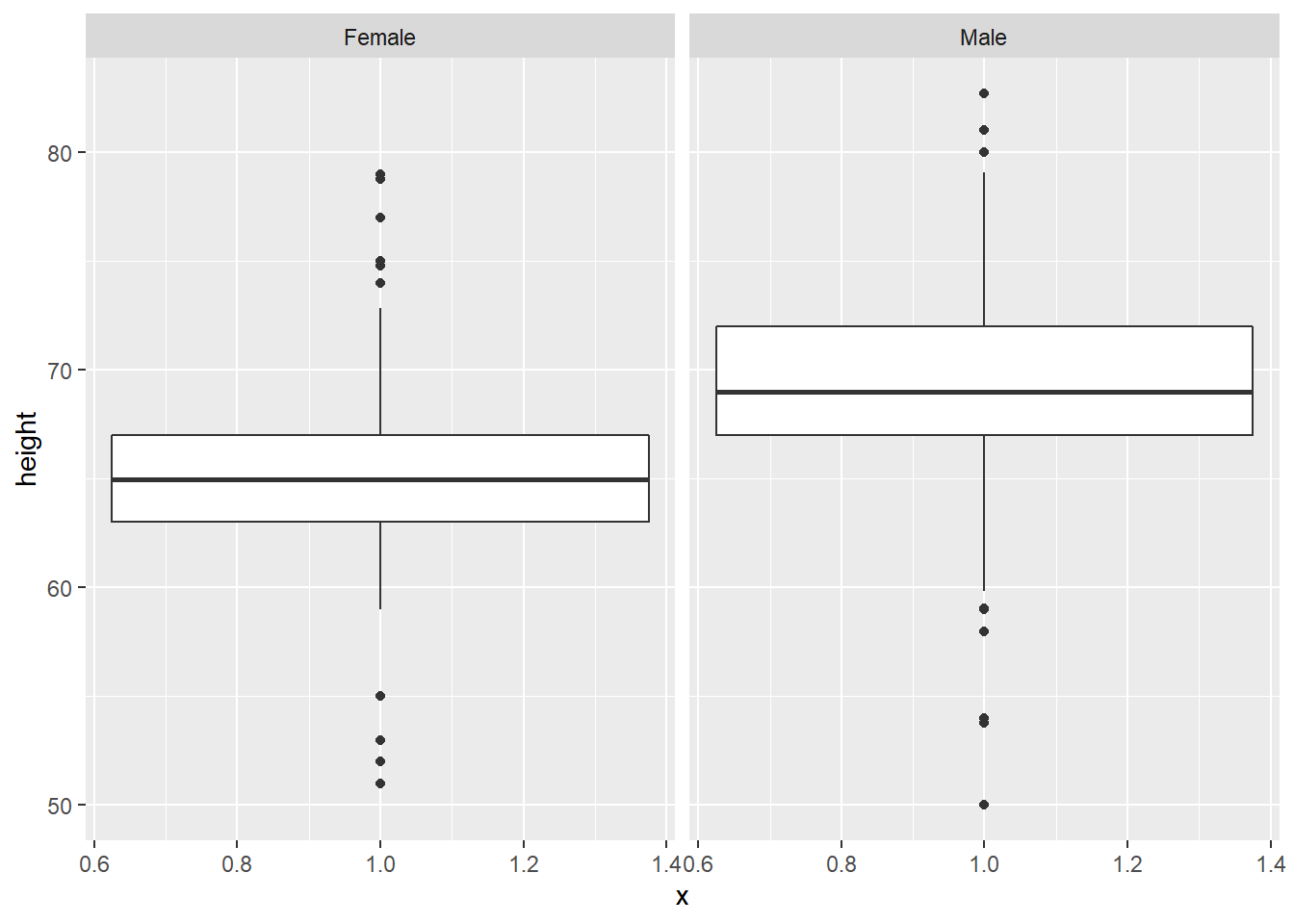
But also, with boxplots, it might be clearer to compare within the same plot, by setting sex as the x axis variable:
# boxplot comparison
gg_height_box <- ggplot(data = heights, aes(x = sex, y = height)) +
geom_boxplot()
gg_height_box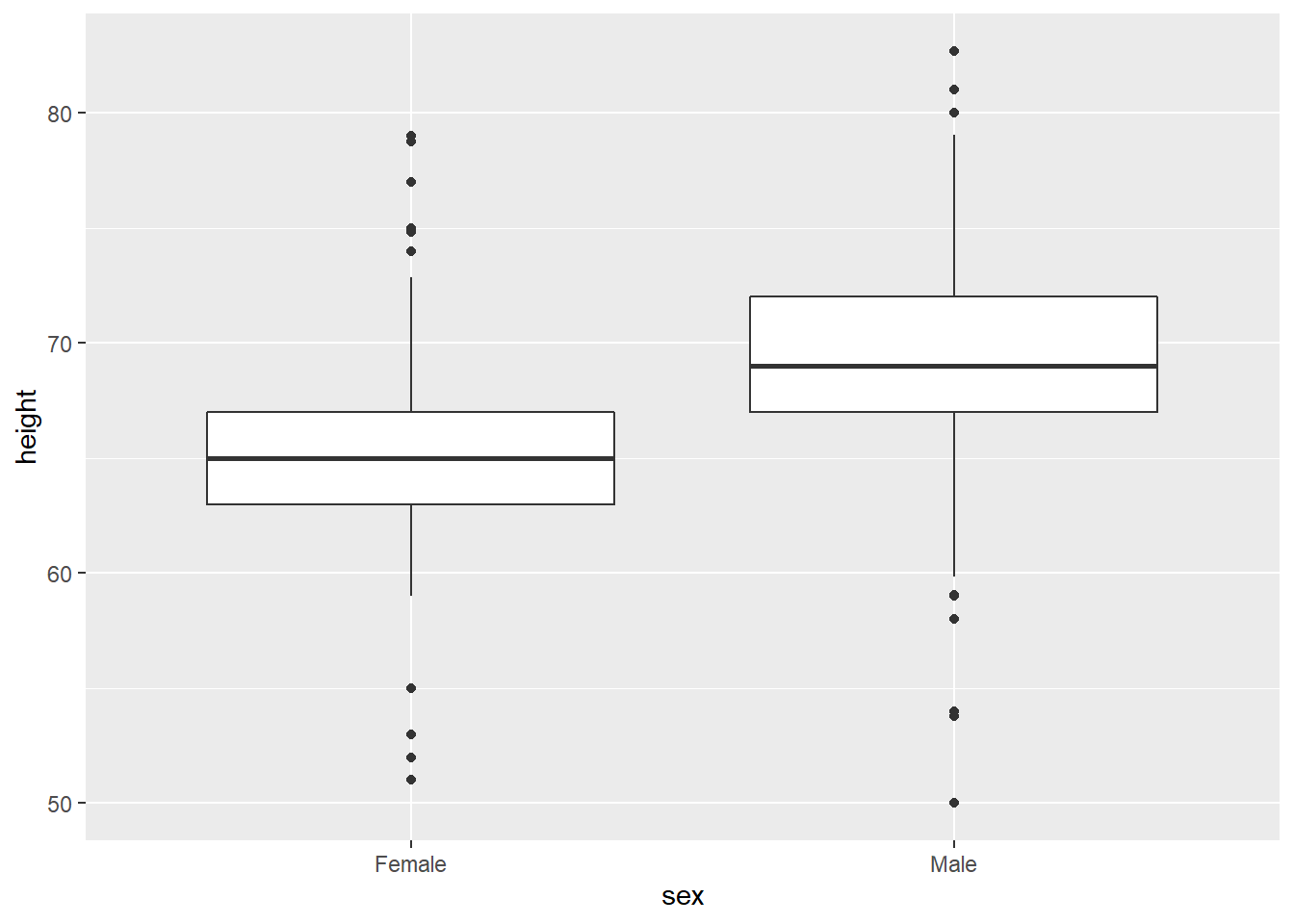
3.1.7 Exercises
Note: some of these exercises might be slightly tricky this week. Just have a go at them, and make sure to look at the solutions when they are posted on Monday.
- Load this dataset about penguins:
# read in the penguins datafile
penguins <- readRDS(url("https://github.com/QMUL-SPIR/Public_files/blob/master/datasets/penguins.rds?raw=true"))- Inspect the dataframe using
head(),names(), anddim(). - Create a histogram of penguin flipper length.
- How does the distribution of flipper length vary by species? Take your histogram and add a
facet_wraplayer to see this. - Add a title to the faceted plot using the
ggtitle()layer. If you need help, try?ggtitle. - Create a scatterplot to show the relationship between bill depth and bill length. How would you describe this relationship?
- How does this relationship change when we break it down into species? Rewrite your scatterplot code so that the colour of the points varies by species.
- Save this plot using
ggsave(). - What do you observe? Describe your findings.